Introduction : Les objets connectés, également connus sous le nom d'Internet des Objets (IoT), ont révolutionné la manière dont nous interagissons avec le monde qui nous entoure. Ces dispositifs intelligents, capables de se connecter à Internet et de partager des données en temps réel, sont devenus omniprésents dans notre quotidien. Cet article explore l'impact croissant des objets connectés sur notre vie quotidienne, les domaines qu'ils transforment et les défis qui les accompagnent.
I. La diversité des objets connectés :
Les objets connectés englobent une vaste gamme de dispositifs, allant des montres intelligentes et des thermostats intelligents aux réfrigérateurs et aux voitures connectées. Cette diversité offre aux consommateurs des opportunités infinies pour simplifier et améliorer leur vie quotidienne. Les maisons intelligentes, par exemple, intègrent des capteurs et des dispositifs connectés pour automatiser les tâches ménagères, optimiser la consommation d'énergie et renforcer la sécurité.
II. Impacts sur la vie quotidienne :
Les objets connectés ont considérablement amélioré notre efficacité et notre confort. Les montres intelligentes suivent notre activité physique, les réfrigérateurs intelligents permettent de gérer les stocks alimentaires à distance, et les assistants vocaux facilitent le contrôle de divers appareils. Ces innovations simplifient notre vie quotidienne tout en ouvrant la voie à de nouvelles expériences.
III. Transformation de l'industrie et de la santé :
Dans le secteur industriel, les objets connectés révolutionnent la gestion de la chaîne d'approvisionnement, la maintenance prédictive et la surveillance des équipements. Dans le domaine de la santé, les dispositifs portables collectent des données en temps réel, permettant aux professionnels de la santé de surveiller les patients à distance, d'améliorer les diagnostics et de personnaliser les traitements.
IV. Défis et préoccupations :
Cependant, l'essor des objets connectés soulève également des défis, notamment en matière de sécurité et de confidentialité. La collecte massive de données soulève des préoccupations quant à la protection de la vie privée, et la vulnérabilité des dispositifs connectés aux cyberattaques est une source d'inquiétude croissante. Des efforts importants sont nécessaires pour développer des normes de sécurité rigoureuses et assurer la protection des utilisateurs.
Conclusion :
Les objets connectés ont transformé notre manière d'interagir avec le monde, ouvrant la voie à une ère de connectivité intelligente. Alors que ces dispositifs continuent de se développer et de s'intégrer dans tous les aspects de notre vie, il est impératif de trouver un équilibre entre l'innovation technologique et la protection des données personnelles. La révolution des objets connectés est en marche, et son impact continuera de façonner notre avenir de manière significative.
Dans le domaine du développement d'applications modernes, l'architecture cloud est devenue une norme pour garantir la flexibilité, la scalabilité et la résilience. Quarkus, un framework Java nouvelle génération, offre une approche légère et réactive pour développer des applications cloud-native. Dans cet article, nous explorerons les étapes essentielles pour créer une architecture cloud avec Quarkus.
1. Comprendre les principes de l'architecture cloud-native
Avant de plonger dans la création d'une architecture cloud avec Quarkus, il est important de comprendre les principes fondamentaux de l'architecture cloud-native. Cela inclut la modularité, la distribution, l'évolutivité, la résilience et l'automatisation. Quarkus facilite l'adoption de ces principes grâce à ses fonctionnalités et son approche de développement.
2. Concevoir l'architecture de l'application
La première étape consiste à concevoir l'architecture de votre application cloud avec Quarkus. Identifiez les différents composants et services nécessaires pour répondre à vos besoins. Quarkus prend en charge diverses options de déploiement, telles que Kubernetes, AWS Lambda et Azure Functions, ce qui vous permet de choisir l'architecture qui convient le mieux à votre cas d'utilisation.Pour concevoir l'architecture cloud de votre application avec Quarkus, vous pouvez envisager une architecture en couches. Par exemple, vous pouvez créer une couche de présentation avec une interface utilisateur en utilisant Quarkus avec le framework Front-end Java Vaadin.
3. Développer les microservices avec Quarkus
Une architecture cloud repose souvent sur des microservices, qui sont des éléments indépendants et modulaires. Utilisez Quarkus pour développer vos microservices en utilisant les extensions pertinentes fournies par le framework. Quarkus offre une prise en charge native des conteneurs, ce qui permet des temps de démarrage rapides et une faible consommation de mémoire, essentiels pour une architecture cloud performante.Quarkus facilite le développement de microservices performants. Par exemple, vous pouvez créer un microservice de traitement de paiement en utilisant Quarkus avec le framework de persistance Hibernate pour interagir avec une base de données relationnelle.
4. Utiliser les services cloud
Intégrez les services cloud appropriés dans votre architecture Quarkus. Par exemple, vous pouvez utiliser les services de bases de données gérées, les files d'attente, les services de messagerie, les caches distribués, etc. Quarkus offre des extensions pour se connecter facilement à ces services, ce qui vous permet de tirer parti des fonctionnalités offertes par les fournisseurs de cloud.Intégrez les services cloud dans votre architecture Quarkus pour tirer parti des fonctionnalités offertes. Par exemple, vous pouvez utiliser le service de messagerie d'Amazon Simple Queue Service (SQS) avec Quarkus en utilisant l'extension AWS SDK pour Java pour une communication asynchrone entre vos microservices.
5. Mettre en œuvre la scalabilité et la résilience
Une architecture cloud doit être capable de faire face à des charges variables et de résister à d'éventuelles pannes. Quarkus propose des fonctionnalités pour la mise en œuvre de la scalabilité et de la résilience, telles que l'équilibrage de charge, la mise en cache, la gestion des erreurs et la récupération automatique. Exploitez ces fonctionnalités pour garantir des performances optimales et une disponibilité continue de vos applications.Quarkus offre des fonctionnalités pour mettre en œuvre la scalabilité et la résilience. Par exemple, vous pouvez utiliser Quarkus avec le système de messagerie Apache Kafka pour créer une architecture de traitement des événements distribuée et résiliente.
6. Déployer sur le cloud
Une fois que vous avez développé votre application avec Quarkus, il est temps de la déployer sur le cloud. Quarkus offre une intégration transparente avec les plateformes de déploiement cloud populaires, telles que Kubernetes, Amazon Web Services (AWS), Microsoft Azure et Google Cloud Platform (GCP). Suivez les bonnes pratiques de déploiement pour assurer une configuration et une gestion efficaces de votre application dans le cloud. Une fois que vous avez développé votre application avec Quarkus, vous pouvez la déployer sur une plateforme cloud. Par exemple, vous pouvez déployer votre application Quarkus sur Kubernetes en utilisant les fonctionnalités natives de Quarkus pour les conteneurs.
Conclusion: Quarkus est un framework puissant qui permet de créer une architecture cloud moderne et performante en utilisant Java. En suivant les exemples donnés dans cet article, vous pouvez concevoir, développer et déployer une architecture cloud avec Quarkus en exploitant ses fonctionnalités avancées. N'hésitez pas à explorer davantage les possibilités de Quarkus et à consulter la documentation pour approfondir vos connaissances et optimiser vos applications cloud.
Les frameworks Java jouent un rôle essentiel dans le développement d'applications modernes. Deux frameworks populaires, Quarkus et Spring Boot, ont émergé comme des choix privilégiés pour la création d'applications Java légères, performantes et évolutives. Dans cet article, nous allons comparer Quarkus et Spring Boot, en mettant en évidence leurs points forts, leurs différences et leurs cas d'utilisation appropriés.
Quarkus : Le framework Java nativement cloud-native
Quarkus est un framework Java conçu spécifiquement pour les applications cloud-native et serverless. Il se distingue par sa faible consommation de ressources, son temps de démarrage ultra-rapide et sa prise en charge optimisée des conteneurs et des architectures orientées microservices. Quarkus s'appuie sur la puissance de la pile JVM (Java Virtual Machine) tout en offrant des performances comparables à celles des langages tels que Go ou Node.js.
Spring Boot : Le leader historique du développement d'applications Java
Spring Boot est un framework Java de renommée mondiale, reconnu pour sa simplicité, sa flexibilité et sa vaste communauté de développeurs. Il facilite la création rapide d'applications Java en fournissant des conventions intelligentes, une configuration automatique et une intégration transparente avec les autres projets Spring. Spring Boot est idéal pour le développement d'applications d'entreprise robustes et évolutives.
Comparaison des caractéristiques clés :
Performances :
Quarkus est optimisé pour les temps de démarrage rapides et une faible consommation de mémoire, ce qui en fait un choix idéal pour les fonctions serverless et les microservices à l'échelle.
Spring Boot offre une large gamme de fonctionnalités et une excellente performance pour les applications d'entreprise, mais peut nécessiter plus de ressources en termes de temps de démarrage et de consommation de mémoire.
Taille de l'application :
Quarkus génère des applications Java légères, avec des tailles d'image Docker réduites, ce qui permet une utilisation efficace des ressources.
Spring Boot génère des applications plus volumineuses en raison de l'inclusion de bibliothèques par défaut, mais offre une modularité permettant de sélectionner uniquement les composants nécessaires.
Écosystème et support communautaire :
Spring Boot bénéficie d'un écosystème mature et d'une vaste communauté de développeurs, offrant une documentation abondante, des tutoriels et des exemples de code.
Quarkus est un framework émergent avec une communauté croissante, bien que plus petite que celle de Spring Boot. Cependant, Quarkus s'appuie sur l'écosystème Java existant, ce qui facilite l'adoption pour les développeurs Spring.
Intégration avec d'autres technologies :
Spring Boot offre une intégration étroite avec d'autres projets Spring, ce qui facilite la mise en place d'applications d'entreprise complètes.
Quarkus offre également une intégration avec d'autres frameworks et outils populaires tels que Hibernate, Eclipse MicroProfile et GraalVM.
Conclusion:
Quarkus et Spring Boot sont deux frameworks Java puissants, chacun avec ses propres forces et cas d'utilisation appropriés. Le choix entre les deux dépend des besoins spécifiques de votre projet et de la préférence de votre équipe de développement. En fin de compte, les deux frameworks offrent des solutions efficaces pour le développement d'applications Java modernes. Il est important d'évaluer attentivement vos exigences et de prendre en compte les avantages et les inconvénients de chaque framework avant de faire un choix éclairé.
Problèmes à ne pas faire dans une architecture Spring Boot et microservices
L'architecture Spring Boot et les microservices sont devenus une tendance populaire dans le développement de logiciels modernes. Cependant, il y a certaines erreurs courantes que les développeurs peuvent commettre lors de la mise en place de cette architecture. Dans cet article, nous allons discuter des problèmes à ne pas faire dans une architecture Spring Boot et microservices.
Concevoir des microservices qui sont trop petits
Lors de la conception de microservices, il est important de ne pas diviser le système en services trop petits. Cela peut entraîner une complexité accrue et des coûts de communication plus élevés entre les services, car chaque service doit communiquer avec de nombreux autres services. Au lieu de cela, chaque microservice doit avoir une responsabilité claire et définie, et être suffisamment grand pour s'occuper de toutes les tâches liées à cette responsabilité.
Utiliser une architecture à trois niveaux
L'utilisation d'une architecture à trois niveaux dans les microservices peut entraîner des problèmes de performance et de communication entre les services. Au lieu de cela, il est préférable d'utiliser une architecture basée sur des événements ou des flux de données, qui permettent une communication asynchrone et une évolutivité plus facile.
Abuser des appels HTTP synchrones
L'utilisation excessive des appels HTTP synchrones peut ralentir les performances des microservices et entraîner des problèmes de latence. Au lieu de cela, il est recommandé d'utiliser des appels HTTP asynchrones ou des messages asynchrones pour améliorer la performance.
Ne pas utiliser un registre de services
Un registre de services est un composant essentiel d'une architecture de microservices. Il permet aux services de découvrir les autres services du système et de communiquer avec eux de manière transparente. Ne pas utiliser un registre de services peut entraîner des problèmes de communication entre les services et des erreurs de configuration.
Ne pas tester suffisamment les microservices
Il est important de tester chaque microservice de manière exhaustive avant de le déployer en production. Ne pas tester suffisamment les microservices peut entraîner des erreurs et des défaillances dans le système, ce qui peut avoir des conséquences graves sur l'ensemble du système.
Ne pas avoir une organisation des logs adéquate
Les logs sont un élément clé de la surveillance et du débogage des microservices. Il est donc important d'avoir une organisation des logs claire et efficace pour faciliter la recherche des problèmes. Les logs doivent être structurés et normalisés pour faciliter la recherche, la corrélation et l'analyse des informations.
Ne pas avoir de stratégie de recherche de problèmes
La recherche de problèmes est un processus complexe et fastidieux, et sans une stratégie claire, il peut être difficile de localiser rapidement les problèmes. Il est donc important d'avoir une stratégie de recherche de problèmes claire qui permet de localiser rapidement les problèmes et d'identifier leur cause racine. Cette stratégie peut inclure l'utilisation d'outils de surveillance, de suivi des performances et de débogage.
Ne pas suivre les meilleures pratiques de journalisation
La journalisation est une partie importante de l'organisation des logs et de la recherche de problèmes. Les développeurs doivent suivre les meilleures pratiques de journalisation, telles que l'utilisation de niveaux de journalisation appropriés, la journalisation d'informations pertinentes pour chaque microservice et la journalisation des erreurs et des exceptions.
Ne pas utiliser d'outils de surveillance et de débogage
Les outils de surveillance et de débogage sont essentiels pour la recherche de problèmes dans une architecture Spring Boot et microservices. Les développeurs doivent utiliser des outils tels que les tableaux de bord de surveillance, les outils de suivi des performances et les outils de débogage pour identifier rapidement les problèmes et les résoudre.
Des outils concrets pour chaque règle dans une architecture Spring Boot et microservices
Voici quelques exemples d'outils concrets que vous pouvez utiliser pour respecter les règles que j'ai mentionnées dans mon article précédent :
Concevoir des microservices qui sont suffisamment grands
Pour vous assurer que chaque microservice a une responsabilité claire et définie, vous pouvez utiliser des outils de modélisation de domaine tels que le Domain-Driven Design (DDD). Le DDD vous aide à découper votre système en domaines spécifiques, ce qui peut faciliter la définition des responsabilités de chaque microservice.
Utiliser une architecture basée sur des événements ou des flux de données
Pour implémenter une architecture basée sur des événements ou des flux de données, vous pouvez utiliser des outils tels que Apache Kafka ou RabbitMQ. Ces outils sont conçus pour gérer la communication asynchrone entre les services.
Utiliser des appels HTTP asynchrones ou des messages asynchrones
Pour implémenter des appels HTTP asynchrones ou des messages asynchrones, vous pouvez utiliser des frameworks de messagerie tels que Spring Cloud Stream. Spring Cloud Stream est un framework qui facilite la création de pipelines de traitement de messages asynchrones entre les microservices.
Utiliser un registre de services
Pour mettre en place un registre de services, vous pouvez utiliser des outils tels que Consul ou Etcd. Ces outils vous permettent de découvrir les services disponibles dans votre système et de gérer les connexions entre eux.
Tester chaque microservice de manière exhaustive
Pour tester chaque microservice de manière exhaustive, vous pouvez utiliser des outils de test tels que JUnit ou Mockito. Ces outils vous permettent de créer des tests automatisés pour chaque microservice, ce qui vous permet de détecter les erreurs et les défaillances dans le système avant de le déployer en production.
Organisation des logs :
ELK Stack (Elasticsearch, Logstash, Kibana) : une suite d'outils open-source qui permet de collecter, de centraliser, d'analyser et de visualiser les logs.
Splunk : un outil de gestion de données qui permet de collecter et d'analyser les logs en temps réel.
Graylog : une plateforme de gestion de logs open-source qui permet de collecter, d'analyser et de stocker les logs.
Stratégie de recherche de problèmes :
Zipkin : un outil open-source de suivi de la performance des microservices, qui permet de visualiser et de suivre les demandes traversant plusieurs microservices.
Jaeger : un autre outil open-source de suivi de la performance des microservices, qui permet également de suivre les demandes traversant plusieurs microservices.
Prometheus : un outil open-source de surveillance de la performance qui permet de surveiller et d'alerter en temps réel sur les problèmes de performance.
Meilleures pratiques de journalisation :
Logback : une bibliothèque de journalisation open-source pour Java qui permet de gérer les logs avec une configuration XML.
Log4j2 : une autre bibliothèque de journalisation open-source pour Java qui permet également de gérer les logs avec une configuration XML.
Loggly : une plateforme de journalisation cloud qui permet de stocker et d'analyser les logs.
Outils de surveillance et de débogage :
New Relic : un outil cloud de surveillance de la performance qui permet de surveiller en temps réel les microservices.
Dynatrace : un autre outil cloud de surveillance de la performance qui permet de surveiller en temps réel les microservices.
VisualVM : un outil open-source de débogage pour Java qui permet de surveiller la mémoire, les threads et les performances de l'application Java.
Ces outils ne sont que quelques exemples parmi de nombreux autres outils disponibles sur le marché. Il est important de choisir l'outil qui convient le mieux à votre entreprise en fonction de vos besoins spécifiques.
En conclusion, la mise en place d'une architecture Spring Boot et microservices peut être complexe, mais en évitant ces erreurs courantes, vous pouvez garantir un système robuste et fiable. Il est important de concevoir chaque microservice avec une responsabilité claire, d'utiliser une architecture basée sur des événements, d'éviter les appels HTTP synchrones excessifs, d'utiliser un registre de services et de tester chaque microservice de manière exhaustive avant de le déployer en production. En suivant ces bonnes pratiques, vous pourrez éviter les problèmes courants qui peuvent entraîner des défaillances et des erreurs dans le système. En outre, il est important de noter que l'architecture Spring Boot et microservices est en constante évolution et que de nouvelles bonnes pratiques peuvent être introduites à mesure que la technologie évolue.
Enfin, il est important de noter que chaque système est unique et que les décisions d'architecture doivent être prises en fonction des besoins spécifiques du système. Les erreurs mentionnées dans cet article ne sont pas exhaustives et il peut y avoir d'autres problèmes à éviter lors de la conception d'une architecture Spring Boot et microservices. Cependant, en évitant les erreurs courantes mentionnées dans cet article, vous pourrez commencer à concevoir un système robuste et évolutif.
De nos jours, la signature électronique est devenue un outil incontournable pour les transactions en ligne. Que ce soit pour signer un contrat, un accord de confidentialité, ou tout autre document important, la signature électronique offre une solution rapide, efficace et sécurisée. Si vous souhaitez créer votre propre signature électronique, voici quelques étapes simples à suivre.
Choisissez un service de signature électronique
Il existe de nombreux services de signature électronique en ligne, tels que DocuSign, Adobe Sign, HelloSign, SignNow, etc. Chacun de ces services offre des fonctionnalités différentes, des plans tarifaires différents et des niveaux de sécurité différents. Il est important de bien comparer les différents services avant de choisir celui qui répond le mieux à vos besoins.
Créez un compte
Une fois que vous avez choisi un service de signature électronique, créez un compte en ligne. Vous devrez fournir vos informations personnelles, telles que votre nom, votre adresse e-mail et votre numéro de téléphone.
Téléchargez le document à signer
Une fois que vous avez créé un compte, vous pouvez télécharger le document que vous souhaitez signer. Vous pouvez le télécharger à partir de votre ordinateur ou à partir d'un service cloud, tel que Dropbox, Google Drive ou OneDrive.
Ajoutez votre signature
Une fois que vous avez téléchargé le document, vous pouvez ajouter votre signature électronique. La plupart des services de signature électronique vous permettent de créer une signature en dessinant avec votre souris ou en téléchargeant une image de votre signature. Vous pouvez également utiliser une signature électronique créée à partir de votre smartphone ou tablette.
Envoyez le document signé
Une fois que vous avez ajouté votre signature électronique, vous pouvez envoyer le document signé à la personne ou à l'entreprise qui en a besoin. Le service de signature électronique enverra une copie du document signé à toutes les parties impliquées dans la transaction.
En résumé, la création d'une signature électronique est un processus simple et facile qui peut être effectué en quelques minutes. En choisissant le bon service de signature électronique, vous pouvez bénéficier d'une sécurité accrue, d'une efficacité accrue et d'une rapidité accrue dans vos transactions en ligne. Alors n'hésitez plus, créez votre propre signature électronique dès aujourd'hui et facilitez votre vie professionnelle et personnelle !
Avec l'essor des technologies modernes de développement de logiciels, l'architecture de microservices est devenue de plus en plus populaire ces dernières années. Cette approche consiste à diviser une application en petits services autonomes qui communiquent entre eux via des API. Cela permet aux développeurs de travailler sur des services individuels et de les déployer séparément, ce qui facilite la maintenance et l'évolutivité de l'application.
Mais comment peut-on dire qu'une application est une architecture de microservices ? Voici quelques éléments clés à considérer :
Découpage de l'application en services autonomes : une application qui suit l'architecture de microservices doit être divisée en services indépendants et autonomes. Chaque service doit avoir son propre objectif et sa propre fonctionnalité, et doit être conçu pour être déployé et mis à l'échelle de manière indépendante.
Utilisation de protocoles de communication : Les microservices communiquent entre eux via des protocoles de communication tels que HTTP/REST, gRPC, ou des protocoles spécifiques. Ces protocoles permettent aux services de communiquer entre eux de manière fiable et efficace, même lorsqu'ils sont déployés sur des machines différentes.
Gestion des données : Les microservices doivent gérer leurs propres données de manière indépendante. Cela signifie que chaque service doit avoir sa propre base de données et qu'il doit être responsable de la gestion de ses propres données. Les services peuvent communiquer entre eux pour échanger des données, mais il est important que chaque service soit responsable de ses propres données.
Utilisation de conteneurs : Les conteneurs sont de plus en plus utilisés pour déployer des applications basées sur l'architecture de microservices. Les conteneurs offrent une solution portable et flexible pour déployer des services individuels, ce qui facilite la mise à l'échelle et la gestion de l'application dans son ensemble.
Scalabilité : L'architecture de microservices permet une mise à l'échelle granulaire des services individuels en fonction des besoins de l'application. Cela signifie que les développeurs peuvent ajouter des ressources uniquement pour les services qui nécessitent une mise à l'échelle, ce qui réduit les coûts et améliore les performances de l'application.
En conclusion, pour déterminer si une application suit l'architecture de microservices, il faut prendre en compte plusieurs éléments clés tels que la découpe en services autonomes, la communication entre les services, la gestion des données, l'utilisation de conteneurs et la mise à l'échelle. Si l'application satisfait à ces critères, elle peut être considérée comme une architecture de microservices.
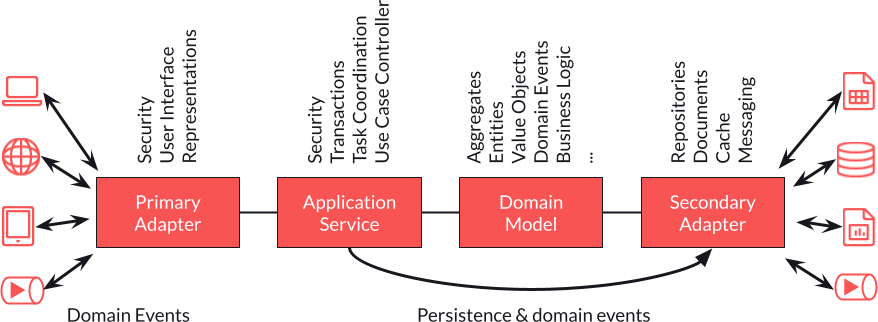
L'architecture hexagonale, également connue sous le nom de "ports-and-adapters" ou "architecture en couches", est un style d'architecture logicielle qui vise à séparer les préoccupations de l'application en isolant le domaine de l'application du code qui s'occupe de la logique de l'infrastructure.
Le principe de base de l'architecture hexagonale est de découper l'application en couches, où chaque couche représente un niveau d'abstraction différent. Au centre de l'architecture se trouve le domaine de l'application, qui contient les règles métier et les comportements clés de l'application. Cette couche est entourée par les adaptateurs, qui sont responsables de la communication avec les autres systèmes, de la manipulation des entrées et des sorties, et de la persistance des données.
L'architecture hexagonale a de nombreux avantages, notamment la facilité de testabilité et de maintenabilité, ainsi que la réduction de la complexité du code. En isolant les différentes parties de l'application, il est possible de développer, tester et déployer chaque couche de manière indépendante. Cela permet également de réduire le couplage entre les différentes parties de l'application, ce qui rend le code plus facile à comprendre et à modifier.
En outre, l'architecture hexagonale est très flexible et peut être adaptée à une grande variété de projets et de technologies. Il est possible d'utiliser cette architecture avec des langages de programmation orientés objet ou fonctionnels, ainsi qu'avec des bases de données relationnelles ou NoSQL.
Cependant, il est important de noter que l'architecture hexagonale peut avoir des coûts initiaux plus élevés en termes de développement, car il faut mettre en place la structure de l'architecture dès le début du projet. Cela nécessite une planification minutieuse et une connaissance approfondie des différentes couches de l'architecture.
En résumé, l'architecture hexagonale est un style d'architecture logicielle qui permet de créer des applications robustes et flexibles en isolant les préoccupations de l'application. Bien qu'il puisse avoir des coûts initiaux plus élevés, les avantages en termes de testabilité, de maintenabilité et de réduction de la complexité du code en font une option intéressante pour de nombreux projets.
Tout d'abord, nous créerons trois packages principaux pour les différentes couches de l'architecture :
com.example.demo
application
domain
infrastructure
Ensuite, nous créons une classe d'entité dans le package de domaine pour représenter notre modèle métier :
package com.example.demo.domain;
public class User {
private Long id;
private String firstName;
private String lastName;
// Getters and setters
}
Nous créons une interface UserRepository dans le package infrastructure pour gérer la persistance des données :
package com.example.demo.infrastructure;
import com.example.demo.domain.User;
public interface UserRepository {
void save(User user);
User findById(Long id);
}
Nous implémentons UserRepository dans une classe UserRepositoryImpl qui utilise JPA pour la persistance des données :
Nous créons un service UserApplicationService dans le package application pour gérer la logique de l'application :
package com.example.demo.application;
import com.example.demo.domain.User;
import com.example.demo.infrastructure.UserRepository;
public class UserApplicationService {
private final UserRepository userRepository;
public UserApplicationService(UserRepository userRepository) {
this.userRepository = userRepository;
}
public void createUser(User user) {
userRepository.save(user);
}
public User getUser(Long id) {
return userRepository.findById(id);
}
}
Nous créons enfin un contrôleur UserController dans le package application pour gérer les requêtes HTTP :
package com.example.demo.application;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
import com.example.demo.domain.User;
@RestController
@RequestMapping("/users")
public class UserController {
private final UserApplicationService userApplicationService;
public UserController(UserApplicationService userApplicationService) {
this.userApplicationService = userApplicationService;
}
@PostMapping("/")
public ResponseEntity createUser(@RequestBody User user) {
userApplicationService.createUser(user);
return ResponseEntity.status(HttpStatus.CREATED).build();
}
@GetMapping("/{id}")
public ResponseEntity getUser(@PathVariable("id") Long id) {
User user = userApplicationService.getUser(id);
return ResponseEntity.ok(user);
}
}
Pour configurer Spring pour utiliser l'architecture hexagonale, nous pouvons utiliser le design pattern d'injection de dépendances en utilisant la fonctionnalité de configuration automatique de Spring :
package com.example.demo;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
import com.example.demo
import com.example.demo.application.UserApplicationService;
import com.example.demo.infrastructure.UserRepository;
import com.example.demo.infrastructure.UserRepositoryImpl;
@SpringBootApplication
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
@Bean
public UserRepository userRepository() {
return new UserRepositoryImpl();
}
@Bean
public UserApplicationService userApplicationService(UserRepository userRepository) {
return new UserApplicationService(userRepository);
}
}
En utilisant cette architecture, nous avons isolé notre modèle métier dans le package de domaine, la persistance des données dans le package infrastructure et la logique de l'application dans le package application. Nous avons également utilisé l'injection de dépendances pour relier les différentes couches entre elles.
Cette architecture permet de faciliter la maintenance et l'évolutivité du code en rendant chaque couche indépendante des autres, en minimisant les dépendances et en améliorant la testabilité grâce à la possibilité de réaliser des tests unitaires sur chaque couche de manière isolée.
En résumé, l'architecture hexagonale est un modèle de conception qui permet de mieux organiser les différentes couches d'une application en isolant le modèle métier dans le package de domaine, la persistance des données dans le package infrastructure et la logique de l'application dans le package application. Cette architecture est particulièrement utile pour les projets à long terme où la maintenance et l'évolutivité du code sont importantes.
L'Event Sourcing est une technique de développement de logiciels qui a gagné en popularité ces dernières années en raison de sa capacité à améliorer la résilience et la scalabilité des systèmes. En utilisant cette technique, un développeur peut stocker l'état d'un système en enregistrant une séquence d'événements plutôt que de stocker uniquement l'état actuel. Dans cet article, nous allons examiner comment implémenter l'Event Sourcing en Java en utilisant un exemple concret.
Qu'est-ce que l'Event Sourcing ?
L'Event Sourcing est une approche de développement de logiciels dans laquelle l'état du système est stocké sous forme de séquence d'événements. Chaque événement représente une modification de l'état du système à un moment précis. En utilisant cette technique, les développeurs peuvent facilement récupérer l'état du système à n'importe quel moment en rejouant simplement les événements.
Cette approche a plusieurs avantages. Tout d'abord, elle offre une résilience accrue. En enregistrant chaque événement, le développeur peut facilement retracer l'historique de toutes les modifications apportées au système. Cela facilite également la détection et la correction des erreurs. De plus, l'Event Sourcing offre une scalabilité améliorée, car il est facile de partitionner les événements pour les stocker dans différents emplacements.
Comment implémenter l'Event Sourcing en Java ?
En Java, l'Event Sourcing peut être implémenté en utilisant une base de données NoSQL. Les bases de données NoSQL sont particulièrement bien adaptées à cette approche car elles offrent une flexibilité accrue par rapport aux bases de données relationnelles traditionnelles.
Exemple concret
Pour illustrer comment implémenter l'Event Sourcing en Java, prenons l'exemple d'un système de réservation de vols.
1. Créer des événements
Pour chaque action effectuée dans le système de réservation de vols, nous créons un événement correspondant. Par exemple, lorsque nous créons une nouvelle réservation, nous créons un événement "ReservationCreatedEvent". Chaque événement est représenté par une classe Java qui contient les informations nécessaires pour décrire l'action effectuée.
Exemple de classe d'événement
public class ReservationCreatedEvent {
private UUID reservationId;
private String passengerName;
private String flightNumber;
public ReservationCreatedEvent(UUID reservationId, String passengerName, String flightNumber) {
this.reservationId = reservationId;
this.passengerName = passengerName;
this.flightNumber = flightNumber;
}
// getters and setters
}
2. Stocker les événements
Pour stocker les événements, nous utilisons une base de données NoSQL telle que Cassandra. Nous créons une table "Reservations" qui contient une colonne "events" de type liste. Pour ajouter un nouvel événement à une réservation, nous pouvons utiliser la méthode "saveEvent" de notre repository.
Exemple de repository
public class ReservationRepository {
private static final String INSERT_EVENT_QUERY = "UPDATE Reservations SET events = events + ? WHERE id = ?";
private static final String SELECT_EVENTS_QUERY = "SELECT events FROM Reservations WHERE id = ?";
private final Session session;
public ReservationRepository(Session session) {
this.session = session;
}
public void saveEvent(UUID id, Object event) {
session.execute(INSERT_EVENT_QUERY, id, toJson(event));
}
public List
3. Rejouer les événements
Pour récupérer l'état actuel d'une réservation, nous devons rejouer tous les événements associés à cette réservation. Pour ce faire, nous pouvons utiliser la méthode "getEvents" de notre repository pour récupérer tous les événements associés à une réservation, puis les rejouer dans l'ordre chronologique pour reconstruire l'état actuel de la réservation.
Exemple de méthode pour récupérer l'état actuel d'une réservation
public class ReservationService {
private final ReservationRepository reservationRepository;
public ReservationService(ReservationRepository reservationRepository) {
this.reservationRepository = reservationRepository;
}
public Reservation getReservation(UUID id) {
List
Dans cet exemple, la classe "Reservation" représente l'état actuel d'une réservation. Lorsque nous rejouons les événements associés à une réservation, nous utilisons les méthodes "createReservation" et "cancelReservation" pour mettre à jour l'état de la réservation en fonction des événements.
Avantages de l'Event Sourcing
L'Event Sourcing présente plusieurs avantages par rapport aux méthodes traditionnelles de développement de logiciels:
Réversibilité: En stockant tous les événements qui se produisent dans un système, nous pouvons facilement revenir en arrière en rejouant simplement les événements dans l'ordre inverse.
Reconstruction de l'état: En rejouant tous les événements associés à une entité, nous pouvons reconstruire son état actuel de manière fiable.
Facilité de mise à l'échelle: En stockant les événements dans une base de données NoSQL, nous pouvons facilement mettre à l'échelle horizontalement en ajoutant des nœuds à notre cluster.
Meilleure traçabilité: En enregistrant tous les événements qui se produisent dans un système, nous pouvons facilement retracer l'historique de toutes les actions effectuées.
Conclusion
L'Event Sourcing est une technique de développement de logiciels puissante qui peut être utilisée pour construire des systèmes fiables, évolutifs et traçables. En utilisant l'Event Sourcing en Java, nous pouvons facilement stocker tous les événements qui se produisent dans un système, récupérer l'état actuel de ce système en rejouant ces événements, et profiter des avantages que cette approche offre.
CQRS (Command Query Responsibility Segregation) - une approche de développement pour améliorer les performances et la scalabilité des applications
L'approche CQRS (Command Query Responsibility Segregation) est une approche de développement qui consiste à séparer les opérations d'écriture et de lecture en utilisant des modèles de données différents. En utilisant cette approche, nous pouvons optimiser les performances et la scalabilité des applications en réduisant la charge sur la base de données et en permettant une gestion plus efficace de l'état de l'application.
Comment fonctionne CQRS ?
CQRS divise une application en deux parties distinctes : une partie pour les opérations d'écriture (ou de commande) et une partie pour les opérations de lecture (ou de requête).
La partie pour les opérations d'écriture traite les commandes pour créer, mettre à jour ou supprimer des données dans l'application. Cette partie est souvent appelée le modèle de commande.
La partie pour les opérations de lecture traite les requêtes pour récupérer des données de l'application. Cette partie est souvent appelée le modèle de requête.
En utilisant des modèles de données différents pour chaque type d'opération, nous pouvons optimiser les performances et simplifier la gestion de l'état de l'application.
Exemple de code Java utilisant CQRS
Voici un exemple de code Java utilisant CQRS pour gérer les opérations de commande et de requête pour une application de gestion de commandes :
public class CreateOrderCommand {
private final String customerId;
private final List orderLines;
public CreateOrderCommand(String customerId, List orderLines) {
this.customerId = customerId;
this.orderLines = orderLines;
}
public String getCustomerId() {
return customerId;
}
public List getOrderLines() {
return orderLines;
}
}
Ensuite, nous créons une classe CommandHandler pour gérer les commandes :
public class CreateOrderCommandHandler {
private final OrderRepository orderRepository;
public CreateOrderCommandHandler(OrderRepository orderRepository) {
this.orderRepository = orderRepository;
}
public void handle(CreateOrderCommand command) {
Order order = new Order(command.getCustomerId(), command.getOrderLines());
orderRepository.save(order);
}
}
Maintenant, nous créons une classe Query pour gérer les opérations de lecture :
public class GetOrderQuery {
private final String orderId;
public GetOrderQuery(String orderId) {
this.orderId = orderId;
}
public String getOrderId() {
return orderId;
}
}
Ensuite, nous créons une classe QueryHandler pour gérer les requêtes :
public class GetOrderQueryHandler {
private final OrderRepository orderRepository;
public GetOrderQueryHandler(OrderRepository orderRepository) {
this.orderRepository = orderRepository;
}
public Order handle(GetOrderQuery query) {
return orderRepository.findById(query.getOrderId());
}
}
Enfin, nous créons une classe Controller pour gérer les requêtes HTTP et les commandes :
@RestController
public class OrderController {
private final CreateOrderCommandHandler createOrderCommandHandler;
private final GetOrderQueryHandler getOrderQueryHandler;
public OrderController(CreateOrderCommandHandler createOrderCommandHandler,
GetOrderQueryHandler getOrderQueryHandler) {
this.createOrderCommandHandler = createOrderCommandHandler;
this.getOrderQueryHandler = getOrderQueryHandler;
}
@PostMapping("/orders")
public ResponseEntity createOrder(@RequestBody CreateOrderCommand command) {
createOrderCommandHandler.handle(command);
return ResponseEntity.ok().build();
}
@GetMapping("/orders/{orderId}")
public ResponseEntity getOrder(@PathVariable String orderId) {
GetOrderQuery query = new GetOrderQuery(orderId);
Order order = getOrderQueryHandler.handle(query);
return ResponseEntity.ok(order);
}
}
Dans cet exemple, la classe CreateOrderCommand représente une commande pour créer une nouvelle commande avec un client et une liste de lignes de commande. Le CreateOrderCommandHandler gère cette commande en créant une nouvelle commande et en la sauvegardant dans le dépôt d'ordres.
La classe GetOrderQuery représente une requête pour obtenir une commande existante en utilisant son identifiant. Le GetOrderQueryHandler gère cette requête en recherchant la commande correspondante dans le dépôt d'ordres et en la renvoyant.
Enfin, la classe OrderController utilise ces deux classes pour exposer des API REST pour les opérations de création et de lecture des commandes.
Avantages de CQRS
L'utilisation de l'approche CQRS peut offrir plusieurs avantages pour les applications, notamment :
Amélioration des performances : En séparant les modèles de données pour les opérations d'écriture et de lecture, nous pouvons optimiser les performances en réduisant la charge sur la base de données et en permettant une gestion plus efficace de l'état de l'application.
Scalabilité améliorée : En permettant une gestion plus efficace de l'état de l'application, nous pouvons rendre l'application plus facilement scalable en ajoutant des nœuds supplémentaires.
Meilleure évolutivité : En séparant les modèles de données, nous pouvons rendre l'application plus facilement évolutive en permettant des modifications indépendantes des opérations de commande et de requête.
Meilleure séparation des responsabilités : En séparant les opérations de commande et de requête, nous pouvons simplifier la gestion de l'état de l'application et réduire les risques de bogues.
Conclusion
CQRS (Command Query Responsibility Segregation) est une approche de développement qui peut aider à améliorer les performances, la scalabilité et l'évolutivité des applications. En séparant les opérations d'écriture et de lecture en utilisant des modèles de données différents, nous pouvons simplifier la gestion de l'état de l'application et optimiser les performances de la base de données. Bien que l'approche CQRS puisse être plus complexe à mettre en œuvre que d'autres approches de développement, elle peut offrir des avantages significatifs pour les applications à forte charge ou à forte concurrence.
Programmation Orientée Objet (POO) : La POO est une approche de développement logiciel qui consiste à créer des objets qui contiennent des données et des méthodes. Les objets peuvent interagir les uns avec les autres pour accomplir des tâches spécifiques.
Architecture hexagonale : Aussi connue sous le nom de "Ports and Adapters", cette approche consiste à séparer les couches applicatives et les dépendances externes (comme les bases de données ou les API) en utilisant des interfaces clairement définies. Cela permet de faciliter la maintenance et la flexibilité de l'application.
Test Driven Development (TDD) : Le TDD est une approche de développement qui consiste à écrire des tests avant de coder la logique de l'application. Cela permet de s'assurer que le code est bien testé et de minimiser les erreurs.
Programmation fonctionnelle : La programmation fonctionnelle est une approche de développement qui se concentre sur les fonctions plutôt que sur les objets. Elle utilise des fonctions pures, c'est-à-dire des fonctions qui n'ont pas d'effets de bord et qui ne modifient pas l'état de l'application, pour améliorer la lisibilité et la maintenabilité du code.
Event Sourcing : L'Event Sourcing est une approche de stockage de données qui consiste à enregistrer toutes les actions (événements) qui modifient l'état de l'application. Cela permet de reconstruire l'état de l'application à partir des événements et de faciliter la gestion des transactions et de la concurrence.
CQRS (Command Query Responsibility Segregation) : Cette approche consiste à séparer les opérations d'écriture (commandes) des opérations de lecture (requêtes) en utilisant des modèles de données différents. Cela permet de simplifier la gestion de l'état de l'application et d'améliorer les performances.
Ces approches peuvent être utilisées seules ou combinées pour créer des applications robustes et maintenables en Java.