Architecture hexagonale
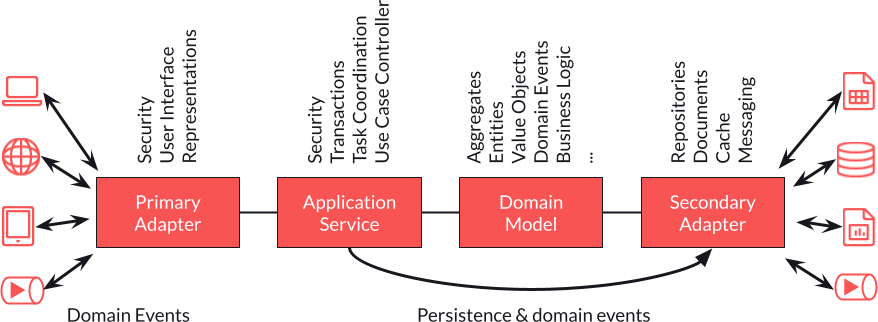
L'architecture hexagonale, également connue sous le nom de "ports-and-adapters" ou "architecture en couches", est un style d'architecture logicielle qui vise à séparer les préoccupations de l'application en isolant le domaine de l'application du code qui s'occupe de la logique de l'infrastructure.
Le principe de base de l'architecture hexagonale est de découper l'application en couches, où chaque couche représente un niveau d'abstraction différent. Au centre de l'architecture se trouve le domaine de l'application, qui contient les règles métier et les comportements clés de l'application. Cette couche est entourée par les adaptateurs, qui sont responsables de la communication avec les autres systèmes, de la manipulation des entrées et des sorties, et de la persistance des données.
L'architecture hexagonale a de nombreux avantages, notamment la facilité de testabilité et de maintenabilité, ainsi que la réduction de la complexité du code. En isolant les différentes parties de l'application, il est possible de développer, tester et déployer chaque couche de manière indépendante. Cela permet également de réduire le couplage entre les différentes parties de l'application, ce qui rend le code plus facile à comprendre et à modifier.
En outre, l'architecture hexagonale est très flexible et peut être adaptée à une grande variété de projets et de technologies. Il est possible d'utiliser cette architecture avec des langages de programmation orientés objet ou fonctionnels, ainsi qu'avec des bases de données relationnelles ou NoSQL.
Cependant, il est important de noter que l'architecture hexagonale peut avoir des coûts initiaux plus élevés en termes de développement, car il faut mettre en place la structure de l'architecture dès le début du projet. Cela nécessite une planification minutieuse et une connaissance approfondie des différentes couches de l'architecture.
En résumé, l'architecture hexagonale est un style d'architecture logicielle qui permet de créer des applications robustes et flexibles en isolant les préoccupations de l'application. Bien qu'il puisse avoir des coûts initiaux plus élevés, les avantages en termes de testabilité, de maintenabilité et de réduction de la complexité du code en font une option intéressante pour de nombreux projets.
- Tout d'abord, nous créerons trois packages principaux pour les différentes couches de l'architecture :
- com.example.demo
- application
- domain
- infrastructure
- Ensuite, nous créons une classe d'entité dans le package de domaine pour représenter notre modèle métier :
- Nous créons une interface UserRepository dans le package infrastructure pour gérer la persistance des données :
- Nous implémentons UserRepository dans une classe UserRepositoryImpl qui utilise JPA pour la persistance des données :
- Nous créons un service UserApplicationService dans le package application pour gérer la logique de l'application :
- Nous créons enfin un contrôleur UserController dans le package application pour gérer les requêtes HTTP :
- Pour configurer Spring pour utiliser l'architecture hexagonale, nous pouvons utiliser le design pattern d'injection de dépendances en utilisant la fonctionnalité de configuration automatique de Spring :
package com.example.demo.domain;
public class User {
private Long id;
private String firstName;
private String lastName;
// Getters and setters
}package com.example.demo.infrastructure;
import com.example.demo.domain.User;
public interface UserRepository {
void save(User user);
User findById(Long id);
}package com.example.demo.infrastructure;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
import com.example.demo.domain.User;
@Repository
public interface UserRepositoryImpl extends JpaRepository, UserRepository {
@Override
default void save(User user) {
saveAndFlush(user);
}
@Override
default User findById(Long id) {
return findOne(id);
}
} package com.example.demo.application;
import com.example.demo.domain.User;
import com.example.demo.infrastructure.UserRepository;
public class UserApplicationService {
private final UserRepository userRepository;
public UserApplicationService(UserRepository userRepository) {
this.userRepository = userRepository;
}
public void createUser(User user) {
userRepository.save(user);
}
public User getUser(Long id) {
return userRepository.findById(id);
}
}package com.example.demo.application;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
import com.example.demo.domain.User;
@RestController
@RequestMapping("/users")
public class UserController {
private final UserApplicationService userApplicationService;
public UserController(UserApplicationService userApplicationService) {
this.userApplicationService = userApplicationService;
}
@PostMapping("/")
public ResponseEntity createUser(@RequestBody User user) {
userApplicationService.createUser(user);
return ResponseEntity.status(HttpStatus.CREATED).build();
}
@GetMapping("/{id}")
public ResponseEntity getUser(@PathVariable("id") Long id) {
User user = userApplicationService.getUser(id);
return ResponseEntity.ok(user);
}
} package com.example.demo;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
import com.example.demo
import com.example.demo.application.UserApplicationService;
import com.example.demo.infrastructure.UserRepository;
import com.example.demo.infrastructure.UserRepositoryImpl;
@SpringBootApplication
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
@Bean
public UserRepository userRepository() {
return new UserRepositoryImpl();
}
@Bean
public UserApplicationService userApplicationService(UserRepository userRepository) {
return new UserApplicationService(userRepository);
}
}En utilisant cette architecture, nous avons isolé notre modèle métier dans le package de domaine, la persistance des données dans le package infrastructure et la logique de l'application dans le package application. Nous avons également utilisé l'injection de dépendances pour relier les différentes couches entre elles.
Cette architecture permet de faciliter la maintenance et l'évolutivité du code en rendant chaque couche indépendante des autres, en minimisant les dépendances et en améliorant la testabilité grâce à la possibilité de réaliser des tests unitaires sur chaque couche de manière isolée.
En résumé, l'architecture hexagonale est un modèle de conception qui permet de mieux organiser les différentes couches d'une application en isolant le modèle métier dans le package de domaine, la persistance des données dans le package infrastructure et la logique de l'application dans le package application. Cette architecture est particulièrement utile pour les projets à long terme où la maintenance et l'évolutivité du code sont importantes.